
In the world of technical SEO, we often hear about Google penalties. Google will penalize your site if it detects:
- Plagiarized content that offers no original information.
- Repetitive content, designed to target certain keywords, but providing no real value.
Content that’s plagiarized or repeated across many pages is what Google calls “duplicate content”.
While content is sometimes duplicated with deceptive intentions, content can also be duplicated by mistake. These mistakes can come from blind spots in your SEO strategy, or from shortcomings in your content marketing efforts. Regardless, duplicate content can be harmful to your SEO and should be fixed.
In this post, we’ll share:
- A clear definition of duplicate content
- Why having duplicate content is an issue for SEO
- What’s keyword cannibalization and how to prevent it
- How to fix duplicate content
What Counts as Duplicate Content?

Duplicate content is content that appears on more than one URL across the web. Content may be duplicated in two different websites, or in several URLs within the same domain.
Most websites have some type of duplicate content. Duplicate content often occurs naturally. For example, the www- and non-www versions of your site can be considered as instances of duplicated content. But at the end of the day, Google is indexing your site once, and the two versions are there just for users’ convenience.
On the other hand, your site may include some tiny bits of repetitive copy. For instance, your website’s slogan or a certain call to action. Another common instance of duplicate content are quotes from third-party websites.
Quotes can enrich your blog posts with new perspectives, and add a lot of value. Google won’t punish you for that. Nor will it punish you for using your slogan repeatedly.
In short: Google punishes the direct reproduction of considerable quantities of content, without adding any original value. If your content isn’t spammy or deceptive, rather than just preventing Google penalties, you should focus on optimizing your existing duplicate content. That way, Google will know what to prioritize when crawling your site.
How Bad Is Duplicate Content?
When we say that Google punishes duplicate content, we’re being a little unprecise. Google’s way of penalizing duplicate content is simply filtering it out, so it doesn’t show on the first page of the search results. It’s not a targeted penalty as much as Google doing what Google does best: Detecting the most authoritative and original content and putting it in front of users.
The effects of Google filtering out your content can differ significantly, depending on whose content you’re duplicating.
If your duplicated material is the result of plagiarism, your page simply won’t appear on the first page of the search results. If you’re repeating your own content across your site, it’s a completely different story.
Let’s dive deeper.
Plagiarized Duplicate Content
As we mention in almost every post: Not even our SEO experts fully know how the Google algorithm works. But there’s one thing we do know, Google ranks content that denotes expertise, authoritativeness and trustworthiness. This principle is often referred to as “the E-A-T formula”.

A website with 10,000 backlinks, containing a long blog post that’s full of lists, references, and multimedia content will outrank an obscure 300-word post with no featured image.
If you take the most successful blog post in your niche and copy it on your new blog, Google will prefer the original. So, stealing high-ranking content simply doesn’t work.
Duplicate Content Coming from Archive Pages
Can duplicate content be bad, even if it wasn’t created maliciously? The answer is yes.
One source of benign content duplication is archive pages. For instance, let’s say your blog’s archive shows substantial snippets from your blog posts. In that case, your archive page and your single posts might be competing for the same keywords.
There are two ways to solve it:
- Tag your archive pages as “noindex”. If you’re on WordPress, you can get it done with your SEO plugin.
- Set your blog posts’ individual URLs as canonical, so Google knows which version of the content they should prioritize.
While plagiarized content keeps your site from reaching the first page of Google, duplicating your own content can prevent your users from seeing the pages you really want them to see.

What Is Content Cannibalization?

Content cannibalization (also known as keyword cannibalization) takes place when several of your website’s URLs target the same keywords. This repetition causes your pages to compete against each other, instead of your competitors.
Keyword cannibalization occurs when you duplicate your own content, but it may also be caused by two pieces of original content.
For instance, let’s say you’re an agency providing SEO services in Los Angeles. You’ve probably created a landing page targeting the keyword “SEO services in Los Angeles”. That page serves a clear commercial purpose. It gives your users information about your services’ competitive advantages and invites them to request a quote.
Now, let’s say you’ve found that a reputable website has published a list of tips to find SEO services in Los Angeles. This post is making waves, and it targets the keyword “SEO services in Los Angeles”.
If you decide to create a similar post for your site, with the exact same keyword, you’ll be forcing that post to compete against your landing page. Let’s say that the post wins. When someone searches for your services on Google, they’ll find your competitors’ landing pages, that great blog post that inspired you, and your own blog post. If they’re just beginning to consider their options, your post may work for them. But, if they’re ready to buy, you may lose them to your competitors’ commercial pages.
Content cannibalization can result in lost leads and a confusing user experience.
How to Identify, Prevent and Remove Duplicate Content
Let’s take a look at what you can do to identify and remove duplicate content.
We recommend to:
- Avoid creating too many pages, as it can be harder to track
- Keep track of your organic keywords and code
- Use “noindex, no follow” tags
- Use canonical URLs
Keep your site efficient
It’s often believed that the larger the website, the higher the chances of making it to Google’s first page. But, especially if you’re working with a small SEO and development team, the larger the website, the higher the chance of making SEO mistakes. Duplicates can easily slip through if you have 200 different URLs. Especially if you’re not running automated SEO tests.
We could suggest that you make sure every page on your site has a clear purpose. But it’s easier said than done, especially in certain niches. For instance, it’s not uncommon for online marketplaces to be full of redundant pages. There is a slight upside to it. When Amazon competes against itself to rank for a product category, the search results will show you several different links, all coming from Amazon.
But still, it can be frustrating and confusing. To offer users a better experience navigating your site, consider using very specific keywords for product categories or certain pieces of content.
Keep track of your organic keywords & code
Want to take a quick look at your site to see whether there are any duplicates? Check which URLs are ranking for which organic keywords. You can do this with your SEO tool of choice. If you find that there are several URLs ranking for the same organic keyword, it might be an instance of duplicate content.
You can detect duplication through keywords by using an SEO-focused code auditing tool. This type of tool can help you track when a keyword has been added or removed from a page. It can also help you verify whether your efforts to remove duplicate content are being effective. For instance, SEORadar will tell you whether you’ve successfully added a noindex tag to your blog’s archive page.
Use noindex tags strategically
As we’ve already explained in this post, you can use the noindex tag strategically, to prevent Google from crawling pages that may count as duplicate content. Adding a noindex nofollow tag is as simple as going to your page’s source code, and adding this snippet to the header:
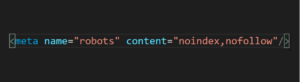
You can get this done with a WordPress plugin. If you’re not on WordPress and have access to a development team, your developers could do it for you. You want to make sure the no index no follow tags are added to a specific page, not to your entire website.
Set canonical URLs
This is another tip that we’ve already discussed very briefly, but that is worth repeating. With canonical URLs, you can:
- Make sure Google prioritizes the pages that matter to you the most.
- Prevent Google from believing that you are plagiarizing yourself if you do cross-posting.
Let’s say you post your articles on your blog and on LinkedIn, Medium, or any other platform that makes you more findable. By setting a canonical URL, you can help Google to decide whether to prioritize the post on your site or to prioritize the Medium version of your post.
Preventing SEO Disasters Has Never Been So Easy
Keeping your website’s code healthy and SEO-optimized demands time and resources. SEORadar keeps an eye on your website’s code so you don’t have to. Get alerts anytime your site’s code changes, so you can fix any issues before they affect your SERP position.
Discover SEORadar today. Want to see it for yourself? Start a free trial.

